Beyond eMuseum and Search Silos
Gallery Systems is a major player in the museum sector, especially known for its TMS (The Museum System) collection management software. Their eMuseum platform enables museums to publish their collections online, accessible through a website and API.
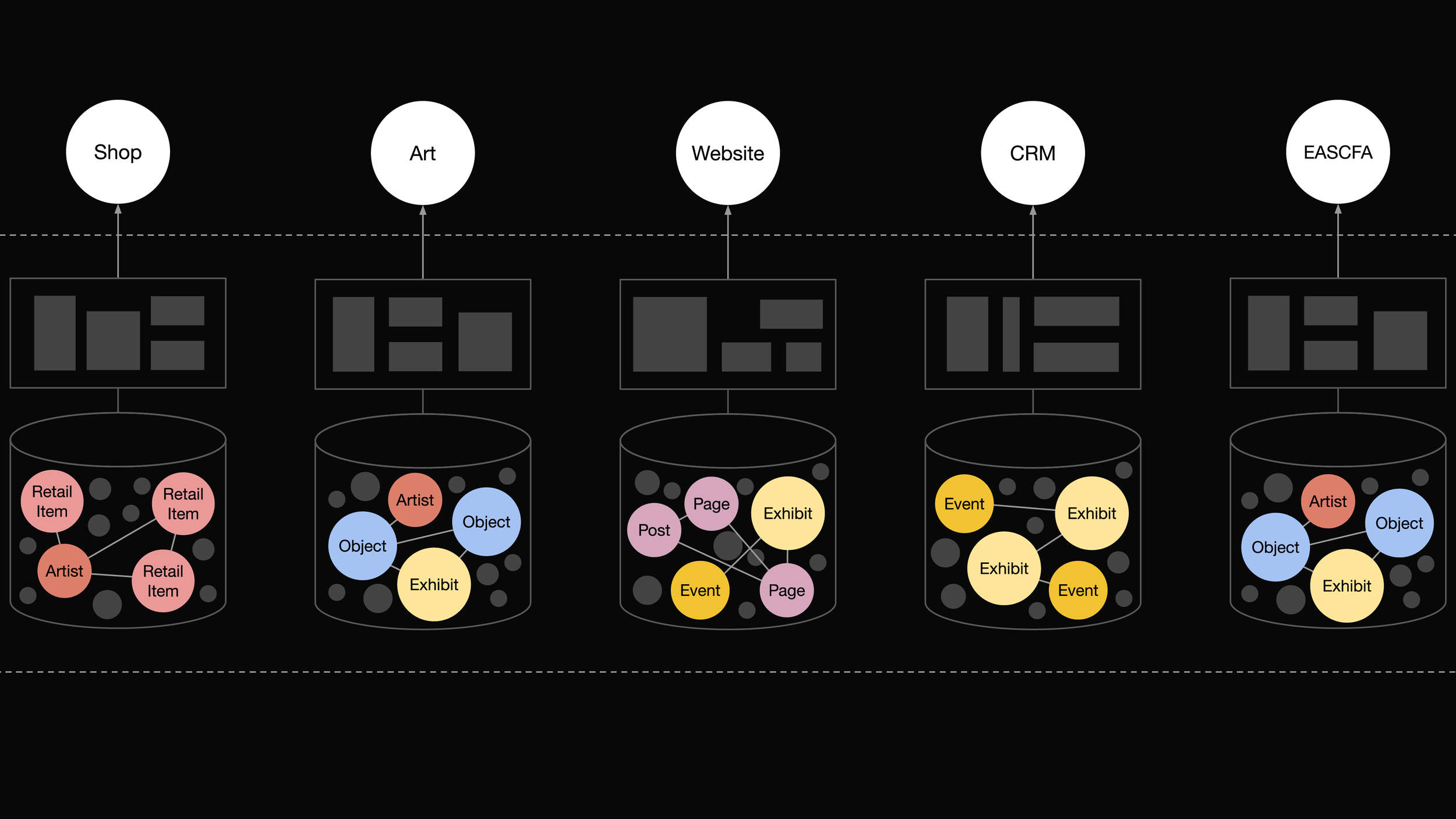
Any tool that enables museums to publish their collections online is beneficial, but specialized web applications like eMuseum lead to fragmented search experiences. Visitors encounter multiple search silos – for the website, collections, libraries, archives, shop, and even job listings. Ideally, users should be able to enter a query like “Picasso” and get results encompassing events, exhibitions, web pages, retail items, educational resources, collection artworks, archival documents and everything else related to Pablo Picasso.
Specialized, siloed search applications segregate content and duplicate functionality.
To mitigate this issue, some sites index simplified collection metadata in their basic website search. However, this approach often overlooks the complex nuances of collection metadata and misses out on opportunities to reveal common search facets across different content types. Curious visitors and researchers often hit a wall in these simplified searches and are driven off to 'advanced' search silos.
I propose a solution demonstrated by musefully.org (available on Github), which is a universal faceted search API encompassing all content within a museum's domain. This involves ETL (Extract, Transform, Load) pipelines extracting data from diverse sources such as collections, websites, libraries, archives, and third-party databases. This data then feeds into a search engine like Elasticsearch, which powers a comprehensive search API, making all content readily discoverable.
Diagram of Universal Search ETL ingest process with optional semantic search functionality. Click for larger image.
Search engines like Elasticsearch are extremely powerful, and when coupled with front-end platforms like Next.js, it becomes relatively straightforward to develop such a system:
Extract datasources. Use SQL scripts or an ORM (Object-Relational Mapping) to efficiently export public data from collections and other databases into accessible text formats like CSV.
Transform the data by normalizing it to align with universal search fields and facets, ensuring consistency and improved discoverability across diverse datasets.
Vectorize (optional). Create embeddings for textual or visual content using tools like OpenAI's CLIP (see results here using artwork images) or Ada v2, enabling semantic search with nuanced, context-aware matching based on the content's deeper characteristics and relationships.
Load transformed data into Elasticsearch index/indices.
Now that all content is in a single search engine, advanced search capabilities with Elasticsearch DSL including vector search are unlocked to enable unified search across all content.
This type of design can take many forms depending upon the unique needs of an organization. For the Brooklyn Museum Search API, the entire ETL and search system is deployed in a Next.js application:
System design for Brooklyn Museum search.